最近由于美国几大传统报业公司的倒闭或关停纸质印刷品,关于Google是否窃取了报纸内容的争论甚嚣尘上。本文选取几篇鞭辟入里的文章或言论(至少我这么认为),摘录于下。
1、
byScott Karp
There is so much misunderstanding flying around about the economics of content on the web and the role of Google in the web’s content economy that it’s making my head hurt. So let’s see if we can straighten things out.
Google isn’t stealing content from newspapers and other media companies. It’s stealing their control over distribution, which has always been the engine of profits in media. Google makes more money than any other media company on the web because it has near monopoly control over content distribution (i.e. like a metro newspaper in the pre web era).
Those who argue that Google is a friend to content owners because it sends them traffic overlook the basic law of supply and demand. The value of “traffic” is entirely relative. The more content there is on the web, the less value that content has — because of the surfeit of ad inventory and abundance of free alternatives to paid content — and thus the less value “traffic” has.
The more content there is on the web, the less money every content creator makes, and the more money Google makes by taking a piece of that transaction.
Nick Carrsums up the problem well:
What Google doesn’t mention is that the billions of clicks and the millions of ad dollars are so fragmented among so many thousands of sites that no one site earns enough to have a decent online business. Where the real money ends up is at the one point in the system where trafficisconcentrated: the Google search engine. Google’soverriding interestis to (a) maximize the amount and velocity of the traffic flowing through the web and (b) ensure that as large a percentage of that traffic as possible goes through its search engine and is exposed to its ads.
The debate over whether Google’s excerpting content on its search result pages is a violation of copyright law, i.e. whether Google is effectively stealing content, overlooks the much more valuable asset that Google is appropriating. Google makes money less by its ability to display that snipet of content and much more by its ability to know that snipet of content is relevant to what the content consumer is looking for — it makes money by its ability to efficiently distribute that content.
And just how does Google know what content is most relevant, trustworthy, and valuable? How does Google know where to send the traffic that yields such diminishing returns?
Everyone talks about Google’s algorithms as if it were some giant artificial intelligence that had its own ability to judge the value of content.
The greatest irony of the web content economy is that Google by itself doesn’t have a clue what content is good or bad. Google is able to deliver relevant search results only because every site on the web helps them figure it out.
Google’s algorithm is based on reading “links” as votes for content. Every time a website links to another website, Google reads that link as a vote. The brilliance of the Google algorithm is its ability to figure out which votes should count more.
But without those links, without those “votes,” Google has nothing.
What Google “steals” from every website isn’t the content — it’s the links.
It’s the links, stupid. And everyone gives Google their links to read — for free!!
Google doesn’t really need your content, because there’s plenty more where it came from. What Google really needs is your links, i.e. your votes for content — it needs your help separating the wheat from the chaff on the web.
Thebacklashagainst URL shorteners and site framing (e.g.DiggBar) is all about who controls the links, and which links Google is going to read and credit.
The key to Google’s monopoly control over content distribution on the web is its ability to judge what’s most relevant in an increasingly large sea of content.
If media companies want to compete with Google, they need to look at the source of its power — judging good content, which enables Google to be the most efficient and effective distributor of content. They also need to look at Google’s fundamental limitation — its judgment is dependent on OTHER people expressing their judgment of content in the form of links. Above all, they need to look at sources of content judgment that Google currently can’t access, because they are not yet expressed as links on the web.
The balance of power on the webcan shift— but only by understanding what the real sources of power are.
新浪的中文译文(原文:http://tech.sina.com.cn/i/2009-04-12/17152994448.shtml):
导读:新闻记者社交网站Publish 2联合创始人兼CEO斯考特·卡普(Scott Karp)今天在该网站撰文称,有许多对网络内容经济以及谷歌在其中所扮演角色的误读,让我们拨云见日,寻找现象背后的本质。
渠道控制权
谷歌并没有从报纸或其它媒体公司手中偷窃内容,其偷窃的只是传统媒体的渠道控制权,而这一直是传统媒体的利润引擎。正是由于谷歌在内容渠道上近乎垄断性的控制,使其创造了比任何其他媒体公司都更多的利润。
因为谷歌可以带来流量从而将该网站看作内容所有者的朋友的人,忽略了基本的供需法则,“流量”的价值是完全相对的。网络上的内容越多,内容的价值就越低。由于网络上存在过量的广告位和丰富的、可代替付费内容的免费信息,反而降低了“流量”的价值。
网络上的内容越多,内容创造者的营收就越少,而为内容到网络提供桥梁的谷歌所赚的钱也越多。《哈佛商业评论》前执行主编尼克·卡尔(Nick Carr)曾对此有精辟的描述。他写道:“谷歌没有提及的是,数以亿计的点击和数百万美元广告收入是如此分散自成千上万的网站中,而这些网站没有任何一家有像样的网络业务。该系统中实实在在的收入归结于流量集中的地方,即谷歌的搜索引擎。谷歌最感兴趣的两个方面是:1)网络流量在数量和速度上的最大化;2)尽可能确保最大比例的流量通过其搜索引擎,并可以显示谷歌的广告。”
对于谷歌在搜索结果页面引用内容是否侵犯版权有诸多争论,包括谷歌是否实际上窃取了内容,但却忽略了谷歌正在窃取的、更有价值的部分。谷歌很少通过显示内容营利,更多地是通过了解内容与内容消费者所寻找信息的相关程度,也就是说,谷歌通过有效地传播内容营利。
判断内容价值
谷歌如何得知内容与用户的相关程度、可信赖性和价值?谷歌如何得知去哪里发送类似上文所述的价值递减流量?每个谈论谷歌运算法则的人,都认为好像是某些非凡的人工智能有能力判断内容的价值。网络内容经济最大的讽刺在于,谷歌本身对内容好坏一无所知,该网站可以提供相关搜索结果只是因为网络上的所有网站帮他们做到了这一点。
谷歌的运算法基于读取链接并将其作为对特定内容的“投票”。一个网站每次连接到其他网站,谷歌就将此链接视为一个“投票”,谷歌运算法则的精髓在于其可以发现应该更多地计算哪个投票。但如果没有这些链接,没有这些“投票”,谷歌将什么都没有。所以,谷歌真正“窃取”的不是网站的内容,而是所有网站的链接,而这些网站则免费提供链接给谷歌。
谷歌真正需要的不是内容,因为网络上有很多这样的内容。谷歌真正需要的是链接,也就是对内容的“投票”,该搜索引擎需要其他网站的帮助以甄别优劣。谷歌用以对网络上内容渠道进行控制的运算法则的关键是可以在日益增加的海量内容中判断最为相关的内容。
如果媒体公司希望与谷歌竞争,他们需要寻究其权力的源泉,即判断优秀内容,而这一点让谷歌成为最有效率的内容渠道。媒体公司还需要了解谷歌根本的局限性,即该网站依赖其他人对内容的判断。最重要的是,媒体公司需要了解谷歌无法访问的、内容判断的根源,这些内容在网络上还不存在链接。
网络上的权力平衡可以改变,但必须要了解真正的权力根源。(肖恩)
2.
1/3 of Tribune’s traffic comes from a search engine.
70% of that 1/3 comes from Google.
Google is both a competitor and a partner.
Newspapers did this to themselves by not embracing the web properly and fast enough. They were too busy convincing themselves the web wasn’t a threat.
Meanwhile, search engines became the destination for news instead of local newspaper websites.
Now it’s the job of the newspapers to figure out how to be the destination again. Learn from the mistakes of old thinking. Take back the distribution they once had a monopoly on in their markets and they unknowingly handed off to search engines.
If you only knew the plans that Tribune has in the works in this regard. Whether we/Tribune succeed or not is yet to be determined. But we will most definitely give it one hell of shot. I hope the other newspapers are doing the same.
I am, however, not waving the ‘death to Google’ flag. I am simply waving the flag of ’survivorship of traditional journalism’ flag. Just as I can not imagine a world without Google or other search engines, I can not imagine a world without traditional journalism. Traditional journalism isn’t possible without the newspapers cornering enough of the pie to make the numbers work. I’m not saying that every newspaper has to be everything to everyone but they need to continue to do that which others can’t. That takes people . . . that takes resources . . . that takes money . . .
NOTE: My opinions are my own and may or may not represent the opinions of my employer. I am not a journalist. I am a search engine marketer.
3.
Thank you for helping get the word out about Google! Unfortunately, I don’t think the links are relevant enough any more that if all users decided to e.g. nofollow,noindex everything it would matter. As Martin mentions, AdSense/AdWords drives so much more Google revenue than the search itself, but even that isn’t the problem. Google has their hands in everything: They’re in your Docs, your Ads, your Sites, your conferences, your Web 2.0, and now even your cookies:
Google AdSense Privacy Concerns
I think Google, like GM and the banks, has become “too big to fail” - even if all of the honest webmasters and surfers removed AdSense, changed search engines, deleted their Gmail accounts, and stopped using all of Google’s analytics, keyword research, and webmaster tools, we would just see them replaced with made-for-adsense crap and black hats looking to make a quick buck (as we are seeing to some extent already).
I hope we can find a reasonable solution to the Google problem, but it is extremely unlikely - especially considering Google’s (”alleged”)ties to the FBI, CIA, NSA, and others.
4. Google in The Middle (原文:http://www.roughtype.com/archives/2009/04/google_in_the_m.php)
Three truths:
1. Google is a middleman made of software. It's a very, very large middleman made of software. Think of what Goliath or the Cyclops or Godzilla would look like if they were made of software. That's Google.
2. The middleman acts in the middleman's interest.
3. The broader the span of the middleman's control over the exchanges that take place in a market, the greater the middleman's power and the lesser the power of the suppliers.
For much of the first decade of the Web's existence, we were told that the Web, by efficiently connecting buyer and seller, or provider and user, would destroy middlemen. Middlemen were friction, and the Web was a friction-removing machine.
We were misinformed. The Web didn't kill mediators. It made them stronger. The way a company makes big money on the Web is by skimming little bits of money off a huge number of transactions, with each click counting as a transaction. (Think trillions of transactions.) The reality of the web ishypermediation, and Google, with its search and search-ad monopolies, is the hypermediator.
Which brings us to everybody's favorite business: the news. Newspapers, or news syndicators like the Associated Press, bemoan the power of the middlemen, or aggregators, to get between them and their readers. They particularly bemoan the power of Google, because Google wields, by far, the greatest power. The editor of the Wall Street Journal, Robert Thomson,callsGoogle a "tapeworm." His boss, Rupert Murdoch, says Google is engaged in "stealing copyrights."
Others see Thomson and Murdoch as hypocritical crybabies. To them, Google is the good guy, the benevolent middleman that fairly parcels out traffic, by the trillions of page views, to a multitude of hungry web sites. It's the mommy bird dropping little worm fragments into the mouths of all the baby birds. Scott Rosenbergpoints outthat Google makes it simple for newspapers or any other site operators to opt out of its general search engine and all of its subsidiary search services, including Google News. "Participation in Google is voluntary," he writes. Yet no one opts out. Participation is not only voluntary but "is also pretty much universal, because of the benefits. When users are seeking what you have, it’s good to be found."
Rosenberg is correct, but he misses, or chooses not to acknowledge, the larger point. When a middleman controls a market, the supplier has no real choice but to work with the middleman -even if the middleman makes it impossible for the supplier to make money. Given the choice, most people will choose to die of a slow wasting disease rather than to have their head blown off with a bazooka. But that doesn't mean that dying of a slow wasting disease is pleasant.
As Tom Sleeexplains, Google's role as the dominant middleman in the digital content business resembles Wal-Mart's role as the dominant middleman in the consumer products business. Because of the vastness of Wal-Mart's market share, consumer goods companies have little choice but to sell their wares through the retailing giant, even if the retailing giant squeezes their profit margin to zilch. It's called leverage: Play by our rules, or die.
Sometimes "voluntary" isn't really "voluntary."
When it comes to Google and other aggregators, newspapers face a sort of prisoners' dilemma. If one of them escapes, their competitors will pick up the traffic they lose. But if all of them stay, none of them will ever get enough traffic to make sufficient money. So they all stay in the prison, occasionally yelling insults at their jailer through the bars on the door.
None of this, by the way, should be taken as criticism of Google. Google is simply pursuing its own interests - those interests just happen to be very different from the interests of the news companies. What Google can, and should, be criticized for is its disingenuousness. In an official response to the recent criticism of its control over news-seeking traffic, Google rolled out one of its lawyers, who put on his happy face and wrote: "Users like me are sent from different Google sites to newspaper websites at a rate of more than a billion clicks per month. These clicks go to news publishers large and small, domestic and international - day and night. And once a reader is on the newspaper's site, we work hard to help them earn revenue. Our AdSense program pays out millions of dollars to newspapers that place ads on their sites."
Wow. "A billion clicks." "Millions of dollars." Such big numbers. What Google doesn't mention is that the billions of clicks and the millions of ad dollars are so fragmented among so many thousands of sites that no one site earns enough to have a decent online business. Where the real money ends up is at the one point in the system where trafficisconcentrated: the Google search engine. Google'soverriding interestis to (a) maximize the amount and velocity of the traffic flowing through the web and (b) ensure that as large a percentage of that traffic as possible goes through its search engine and is exposed to its ads. One of the most important ways it accomplishes that goal is to promote the distribution of as much free content as possible through as many sites as possible on the web. For Google, any concentration of traffic at content sites is anathema; it would represent a shift of power from the middleman to the supplier. Google wants to keep that traffic fragmented. The suppliers of news have precisely the opposite goal.
Take a look at the top topic on Google News right now:
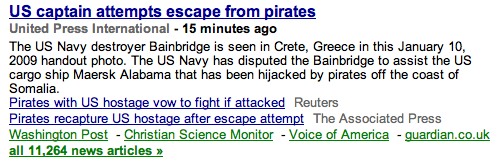
Look, in particular, at the number of stories on this topic that Google already has in its database: 11,264. That's a staggeringly large number. To Google, it's a beautiful number. To the 11,264 news sites competing for a measly little page view, and the infinitesimal fraction of a penny the view represents, it's death.
As I've written before, the essential problem facing the online news business isoversupply. The cure isn't pretty. It requires, first, a massive reduction of production capacity - ie, the consolidation or disappearance of lots of news outlets. Second, and dependent on that reduction of production capacity, it requires news organizations to begin to impose controls on their content. By that, I don't mean preventing bloggers from posting fair-use snippets of articles. I mean curbing the rampant syndication, authorized or not, of full-text articles. Syndication makes sense when articles remain on the paper they were printed on. It doesn't make sense when articles float freely across the global web. (Take note, AP.)
Once the news business reduces supply, it can begin to consolidate traffic, which in turn consolidates ad revenues and, not least, opens opportunities to charge subscription fees of one sort or another - opportunities that today, given the structure of the industry, seem impossible. With less supply, the supplier gains market power at the expense of the middleman.
The fundamental problem facing the news business today does not lie in Google's search engine. It lies in the structure of the news business itself.
分享到:




